Per un mio grosso cliente di Milano, sto dirigendo tecnologicamente lo sviluppo di un portale basato su ASP.NET 2.0, dove, funzionalmente, è richiesta l'integrazione di certe logiche di workflowing nella gestione dei loro processi aziendali.
A tale scopo ho proposto l'utilizzo di Windows Workflow Foundation, in modo da poter testare sul campo (al di là di semplici applicazioni di prova), nel contesto dello sviluppo di un grosso progetto di classe enterprise questa nuova interessante tecnologia di Microsoft.
Dopo qualche ora di ricerca sono riuscito ad accumulare abbastanza conoscenza per mettere sù un proof of concept al fine di collaudare le idee ed ipotesi che avevo maturato. Allegata a questo post, c'è una applicazione ASP.NET di esempio derivata da quel mio primo prototipo.
La Web Application di Esempio
E' possibile scaricare l'applicazione di esempio qui: WwfExample.rar (386,08 KB).
L'applicazione (la solution) consta di due progetti: la Web Application ed il progetto Workflows, che racchiude tutto il codice specifico che consuma i servizi di Workflow Foundation (WF).
Prima di poter utilizzare l'applicazione in questione, è necessario "attaccare" il file di database fornito alla istanza di SQL Server 2005 Express presente sulla macchina di sviluppo.
L'applicazione utilizza tre tabelle per mantenere il suo stato:
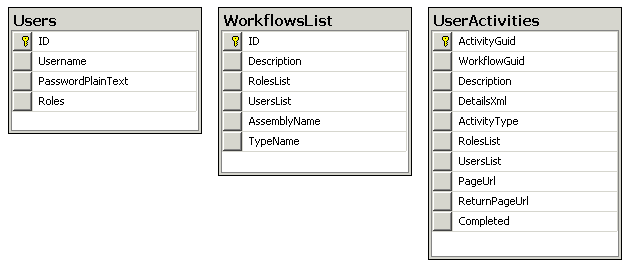
La tabella Users mantiene una lista di tutti gli utenti abilitati ad utilizzare l'applicazione, con relativi ruoli separati da virgola. La tabella WorkflowsList mantiene una lista di tutti i workflow che l'applicazione è abilitata a far partire, con, annesse, informazioni circa quali utenti e quali gruppi hanno tale privilegio e, soprattutto, indicazioni circa il tipo .NET e l'assembly dal quale recuperare la definizione della classe di Workflow. La tabella UserActivities mantiene uno stato della applicazione "parallelo" a quello del Workflow ed è la tebella che viene consultata dal sistema per capire in quale stato si trova l'intera applicazione. I record in questa tabella vengono aggiunti direttamente dalle Activity del Workflow ed essa è una prima ma importante forma di comunicazione tra codice ASP.NET e codice di Workflow Foundation.
Sono inoltre presenti anche queste due tabelle:
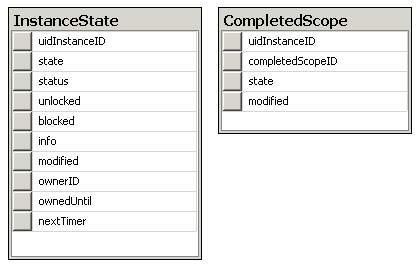
In particolare, la tabella InstanceState viene utilizzata da Workflow Foundation (specificatamente dal servizio SqlWorkflowPersistenceService) per persistere lo stato di un determinato Workflow: il Workflow viene serializzato attraverso il BinaryFormatter, poi compresso, quindi depositato nel campo blob state di questa tabella. Per creare queste due tabelle, e relative stored procedure, è necessario recuperare ed eseguire gli script presenti tipicamente qui:
C:\WINDOWS\Microsoft.NET\Framework\v3.0\Windows Workflow Foundation\SQL\EN\SqlPersistenceService_Schema.sql
C:\WINDOWS\Microsoft.NET\Framework\v3.0\Windows Workflow Foundation\SQL\EN\SqlPersistenceService_Logic.sql
NOTA: nel file di db incluso in questo esempio, le tabelle e le stored procedure di WF sono già presenti.
Fatta partire, l'applicazione mostra una semplice mascherina di login:
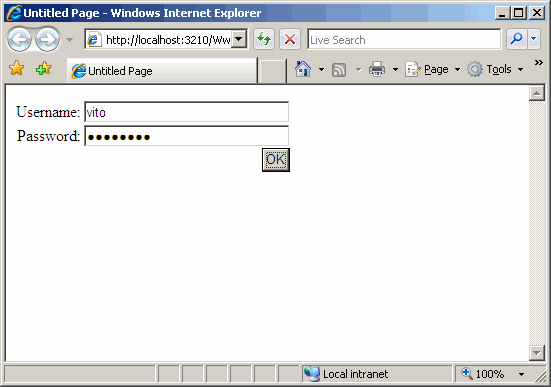
Dove viene appurato il nome dell'utente e, soprattutto, i ruoli a lui assegnati (tramite lookup su db). Verificata la veridicità delle credenziali, viene creato un FormsAuthenticationTicket contenente le informazioni di interesse applicativo sull'utente.
Immediatamente dopo si accede alla form principale dell'applicazione di esempio:
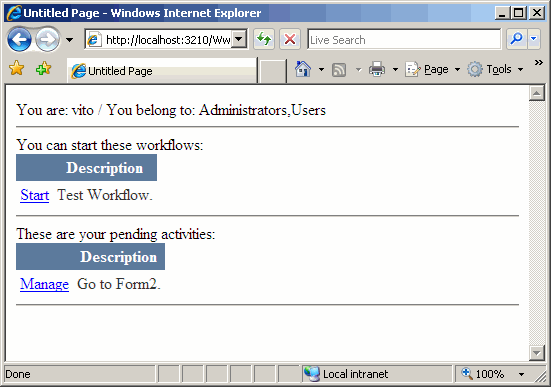
Questa form permette di avviare un dato workflow (se si dispone delle autorizzazioni necessarie per poterlo fare) e di gestire attività pendenti (sempre se si è autorizzati a farlo). La griglia delle attività pendenti (la seconda) viene popolata attraverso la tabella UserActivities su database, che a sua volta viene popolata dal codice del Workflow avviato e gestito dall'applicazione ASP.NET, con nome WorkflowExample.cs:
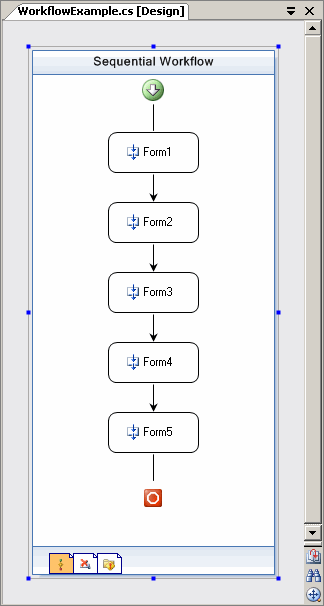
Questo semplice workflow sequenziale definisce una serie di form ASP.NET da visualizzare una dopo l'altra. A ciascuna form sono associati diritti a livello di utente e ruolo, in modo che soltanto gli utenti abilitati abbiano modo di accedervi. E' naturalmente possibile definire workflow di una complessità molto superiore rispetto a quella del workflow qui rappresentato. Nella fattispecie, è possibile inserire qualsiasi tipo di Activity nel flusso di esecuzione del workflow: se necessario, è possibile definire uno stato privato al workflow aggiungendo proprietà (eventualmente bindabili) nel file WorkflowExample.cs. La proprietà bindabile DataSet nella classe Workflows.UserActivity, come spiegato sotto, può essere utilizzata per scambiare dati tra il workflow e l'applicazione ASP.NET.
Da interfaccia utente, in Visual Studio (ossia dal Workflow Designer) è possibile, per ciascuna form, definire proprietà salienti, tra le quali quelle di autorizzazione appena descritte:
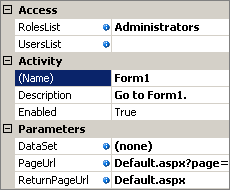
La proprietà DataSet (quando bindata) permette di passare informazioni da una Activity ad un'altra, passando dal codice ASP.NET, nel nostro caso specifico: il sistema, infatti, serializza di volta in volta il contenuto di questa proprietà della Activity nel campo DetailsXml della tabella UserActivities; questo permette al codice della pagina web di modificare il dataset, che poi, trasparentemente, viene ripassato alla Activity del Workflow, in modo che lo stato della proprietà bindabile sia aggiornato opportunamente.
Cliccando su una attività pendente, si accede ad una form di gestione:
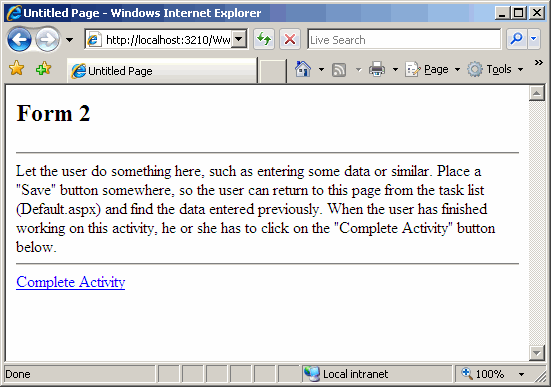
Il link Complete Activity scatena il codice che realizza l'interoperabilità con Workflow Foundation: in questo caso e per il nostro Workflow di esempio, l'attività "Form2" viene chiusa e si passa all'attività "Form3", che è giusto la successiva nel nostro workflow sequenziale.
Il funzionamento dell'intera applicazione è piuttosto semplice, se si intendono i meccanismi di intercomunicazione di WF (vedi code di item, o WorkflowQueue). Questo schema dovrebbe riassumere a grandi linee ciò che accade:
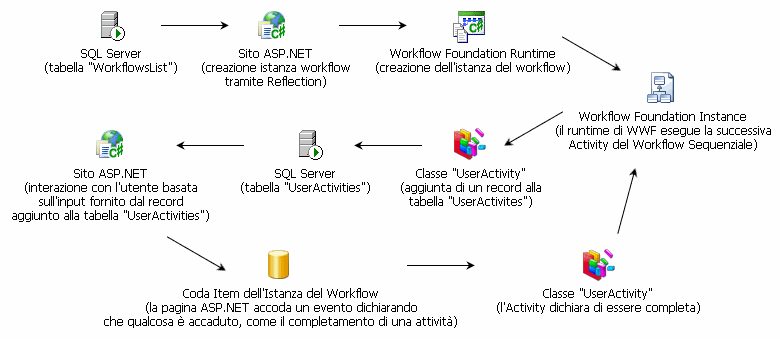
La discussione seguente è un poco più complessa, poichè tratta specificatamente dei problemi di interoperabilità tra ASP.NET e WF e delle soluzioni che ho ricercato e deciso di adottare caso per caso.
Threading
Normalmente, Workflow Foundation utilizza le caratteristiche del servizio DefaultWorkflowSchedulerService per creare e coordinare i thread responsabili dell’esecuzione di tutti i workflow associati ad uno stesso runtime (WorkflowRuntime). Nella fattispecie, questo implica l’esecuzione asincrona delle istanze di workflow gestite da un runtime, che vengono opportunamente e trasparentemente messe nella coda di esecuzione del thread pool .NET associato all’applicazione host.
Nel contesto di una applicazione ASP.NET, questo, generalmente, non è desiderabile. Infatti, il DefaultWorkflowSchedulerService, quando utilizzato in una applicazione web, và ad impegnare un thread aggiuntivo per ciascuna richiesta HTTP che il server di IIS, in un dato momento, sta processando e che richiede le funzionalità di Workflow Foundation. Per indirizzare questo problema, è necessario specificare il servizio ManualWorkflowSchedulerService, quando si inizializza una istanza del WorkflowRuntime:
Runtime = new WorkflowRuntime();
[...]
Runtime.AddService(new ManualWorkflowSchedulerService(true));
[...]
Questo permette di controllare l’esecuzione di un dato workflow, di coordinarla rispetto al thread che sta servendo la richiesta HTTP e di disimpegnare un thread dal thread pool dell’applicazione host, poichè WF và ad eseguire le nostre activity nel contesto dello stesso thread che sta eseguendo la pagina ASP.NET.
Quanto detto è possibile evincerlo empiricamente andando a sbirciare nel call stack .NET durante l’esecuzione dell’applicazione di esempio allegata a questo post:
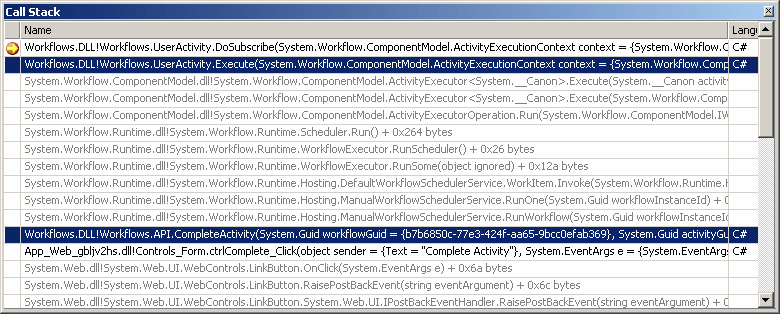
UserActivity.Execute è il nostro codice applicativo che implementa la nostra Activity (il primo contesto evidenziato in blu). API.CompleteActivity (il secondo contesto in blu) è un nostro metodo chiamato direttamente da un gestore eventi di un pulsante di una webform, che chiama l’API ManualWorkflowSchedulerService.RunWorkflow, che provoca l’esecuzione immediata del workflow il cui ID passiamo come parametro. Come anticipato, sia il codice della pagina web che quello del workflow vengono eseguiti nel contesto dello stesso thread.
Transazionalità e Persistenza
La classe TransactionScope (System.Transactions) permette di definire contesti transazionali in codice .NET 2.0 e 3.0 in maniera semplice ed immediata. Specialmente se si utilizza SQL Server 2005, l’uso della classe TransactionScope diviene ancora più semplice, poichè si viene liberati del tutto da tutte quelle considerazioni di cui tener conto circa eventuali, inutili e costosi coinvolgimenti del MSDTC per transazioni puramente locali, importanti invece quando si lavora, per esempio, con SQL Server 2000. Sorvolando sulle specifiche caratteristiche della classe TransactionScope (fuori dagli obiettivi di questo post), nell’esempio fornito viene usata questa nuova funzionalità di .NET 2.0 per la scrittura di codice transazionale che scrive su SQL Server.
Uno dei requisiti principali per realizzare una consistente interoperabilità tra WF e ASP.NET è la corretta gestione della persistenza dei workflow su database. Per comunicare a Workflow Foundation di persistere tutti i workflow relativi ad uno stesso WorkflowRuntime su database, è necessario registrare il servizio SqlWorkflowPersistenceService all’atto della inizializzazione dell’istanza del WorkflowRuntime:
Runtime = new WorkflowRuntime();
[...]
NameValueCollection parameters = new NameValueCollection();
parameters.Add("ConnectionString", connectionString);
parameters.Add("UnloadOnIdle", "false");
Runtime.AddService(new SqlWorkflowPersistenceService(parameters));
[...]
Come parametri, specifichiamo la stringa di connessione al database ed indichiamo al servizio di NON persistere un workflow su database quando questo è inattivo (parametro UnloadOnIdle): infatti, per un maggiore controllo e per ragioni di consistenza transazionale che vedremo tra poco, ci preoccupiamo noi di chiamare il metodo WorkflowInstance.Unload quando intendiamo persistere una istanza di Workflow su db.
Infatti uno dei maggiori problemi quando si intende integrare della logica che accede ad un db in una istanza di Workflow con della logica dello stesso tipo eseguita esternamente nel contesto dell’applicazione host (in questo caso ASP.NET) è che WF, per ragioni di design, impedisce alla transazione ambientale associata al thread di esecuzione nel momento in cui si esegue il workflow (ManualWorkflowSchedulerService.RunWorkflow) di propagarsi fino al contesto di esecuzione nel quale vengono eseguite le Activity del workflow. Questo è possibile evincerlo empiricamente, per esempio, debuggando l’applicazione di esempio di questo post: prima di chiamare l’API ManualWorkflowSchedulerService.RunWorkflow, la proprietà statica System.Transactions.Transaction.Current è correttamente valorizzata, poichè siamo in uno scope transazionale definito da un costrutto TransactionScope. Al contrario, all’interno del metodo UserActivity.Execute (che implementa la nostra activity) tale proprietà statica ha valore nullo, benchè la chiamata al metodo UserActivity.Execute sia originata a partire da del codice configurato per essere transazionale.
Volendo approfondire la questione ed i motivi di tale comportamento, è necessario ritornare al call stack rappresentato all’inizio di questo post: nella fattispecie, in una delle 9 chiamate che separano il codice host dal codice della Activity, WF ha intenzionalmente “soppresso” la nostra transazione ambientale. Alla fine, come risultato, questo ci impedisce di associare del codice che accede al db in una Activity di un Workflow ad una transazione iniziata dall’host.
Volendo scendere nel merito, magari utilizzando l’ottimo .NET Reflector di Roeder e spulciando rapidamente in quei 9 metodi di cui sopra, è possibile trovare la spiegazione di questo comportamento nel metodo System.Workflow.Runtime.WorkflowExecutor.RunSome, che, decompilato, appare così:
internal void RunSome(object ignored)
{
[...]
using (TransactionScope scope = new TransactionScope(TransactionScopeOption.Suppress))
{
try
{
this.FireWorkflowExecutionEvent(this, WorkflowEventInternal.Executing);
this.RunScheduler();
}
catch (Exception exception)
{
[...]
}
finally
{
this.FireWorkflowExecutionEvent(this, WorkflowEventInternal.NotExecuting);
}
scope.Complete();
}
[...]
}
Questo ci obbliga a trovare nuove soluzioni per scrivere sul database in maniera consistente.
La soluzione che ho ricercato ed adottato sfrutta i meccanismi di serializzazione di .NET, per mettere “in coda” una o più operazioni che è necessario associare ad una transazione controllata dal codice host (ossia da noi). Per ottenere l’effetto desiderato, bisogna, per prima cosa, creare una coda di Workflow dove andare ad aggiungere istanze di un nostro tipo custom (con nome DbAccessCallDetails), che rappresenta una chiamata ad un metodo di qualsiasi tipo che interagisce col db. L’idea di base è di registrare semplicemente l’operazione di interazione col db in questa coda (quando si è all’interno di una Activity), quindi, andare a chiamare il metodo che implementa tale operazione in un secondo momento, per esempio all’atto della serializzazione del Workflow su database. Considerando che la coda di Workflow (WorkflowQueue) è un oggetto che appartiene al Workflow e che le nostre istanze di DbAccessCallDetails si trovano depositate in tale coda, quando il servizio SqlWorkflowPersistenceService, tramite il BinaryFormatter, andrà a serializzare, quindi comprimere e persistere su db il nostro Workflow, noi avremo l’occasione che aspettiamo per svuotare la nostra coda e quindi eseguire quei metodi di cui avevamo procrastinato l’esecuzione.
La classe DbAccessCallDetails si presenta semplicemente così:
[Serializable()]
public class DbAccessCallDetails : ISerializable
{
// constructor(s).
public DbAccessCallDetails(Delegate fnParam, object[] psParam)
{
fn = fnParam;
ps = psParam;
}
public DbAccessCallDetails(SerializationInfo info, StreamingContext context)
{
}
// data.
public Delegate fn = null;
public object[] ps = null;
// ISerializable stuff.
void ISerializable.GetObjectData(SerializationInfo info, StreamingContext context)
{
// call the method.
if (fn != null)
fn.DynamicInvoke(ps);
}
}
In breve, quando si cerca di serializzare una istanza di questa classe, viene chiamato il metodo ISerializable.GetObjectData, che semplicemente invoca il metodo ad essa associato. Questo metodo inserisce dei record su db, nel caso del mio esempio (tabella UserActivities).
Come detto precedentemente, la serializzazione del Workflow avviene all’atto della chiamata al metodo WorkflowInstance.Unload. Come emerge da vari documenti e testimonianze su internet, e come può essere approfondito direttamente attraverso Reflector, questo metodo (intenzionalmente) è l’unico pezzo di codice di WF che non sopprime attivamente la transazione ambientale del thread che lo sta chiamando. Questo significa che è possibile associare ad una stessa transazione ambientale gestita dall’host sia la persistenza dell’istanza del Workflow su database, sia il codice rappresentato dalle varie istanze di DbAccessCallDetails eventualmente presenti nella coda del Workflow. Questo “trucco” ci permette di avere sul database uno stato dei dati di interoperabilità tra la nostra applicazione e Workflow Foundation sempre consistenti:
public static void CompleteActivity(Guid workflowGuid, Guid activityGuid, DataSet activityData, System.Web.HttpRequest Request, System.Web.HttpResponse resp)
{
// notify the completion to the wf.
WorkflowInstance wi = Runtime.GetWorkflow(workflowGuid);
wi.EnqueueItem(
activityGuid.ToString(),
new ActivityCompletedEventArgs(activityData),
null, null);
// tell the workflow to progress.
string redirectUrl = null;
using (TransactionScope scope = new TransactionScope())
{
// complete on the db.
using (Workflows.DataTableAdapters.UserActivitiesTableAdapter ta = new Workflows.DataTableAdapters.UserActivitiesTableAdapter())
{
// complete on the db.
ta.CompleteActivity(activityGuid.ToString());
// get the redirect page url.
redirectUrl = (string)ta.GetDataByActivityGuid(activityGuid.ToString()).Rows[0]["ReturnPageUrl"];
redirectUrl = "/" + (Request.ApplicationPath + "/" + redirectUrl).Trim('/');
}
// call the workflow.
Runtime.GetService<ManualWorkflowSchedulerService>().RunWorkflow(workflowGuid);
// persist the workflow on the db.
wi.Unload();
// commit.
scope.Complete();
}
// redirect.
resp.Redirect(redirectUrl);
}
Il metodo CompleteActivity permette di chiudere l’Activity attualmente aperta, di avanzare nell’esecuzione del Workflow (quindi eseguendo le Activity successive) e soprattutto di aggiornare lo stato sul db. Questo avviene all’atto della chiamata al metodo wi.Unload(), che, secondo quanto detto in precedenza, persiste il workflow su db ed esegue le varie istanze di DbAccessCallDetails, tutto quanto associato alla stessa System.Transactions.Transaction (TransactionScope).